{
"cells": [
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Generating random poems with Python #\n",
"\n",
"\n",
"(I never said they would be good poems)
"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
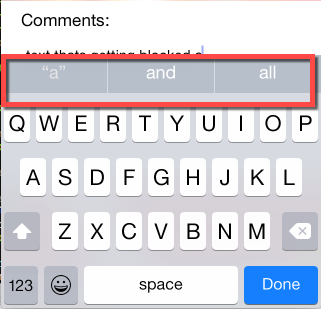
"## Phone autocomplete ##\n",
"\n",
"You can generate random text that sounds like you with your smartphone keyboard:\n",
"\n",
"
\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"## So, how does it work? ##\n",
"\n",
"First, we need a **corpus**, or the text our generator will recombine into new sentences:"
]
},
{
"cell_type": "code",
"execution_count": 1,
"metadata": {
"collapsed": true,
"slideshow": {
"slide_type": "fragment"
}
},
"outputs": [],
"source": [
"corpus = 'The quick brown fox jumps over the lazy dog'"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"Simplest word **tokenization** is to split on spaces:"
]
},
{
"cell_type": "code",
"execution_count": 2,
"metadata": {
"slideshow": {
"slide_type": "fragment"
}
},
"outputs": [
{
"data": {
"text/plain": [
"['The', 'quick', 'brown', 'fox', 'jumps', 'over', 'the', 'lazy', 'dog']"
]
},
"execution_count": 2,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"words = corpus.split(' ')\n",
"words"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"To create **bigrams**, iterate through the list of words with two indicies, one of which is offset by one:"
]
},
{
"cell_type": "code",
"execution_count": 3,
"metadata": {
"slideshow": {
"slide_type": "fragment"
}
},
"outputs": [
{
"data": {
"text/plain": [
"[('The', 'quick'),\n",
" ('quick', 'brown'),\n",
" ('brown', 'fox'),\n",
" ('fox', 'jumps'),\n",
" ('jumps', 'over'),\n",
" ('over', 'the'),\n",
" ('the', 'lazy'),\n",
" ('lazy', 'dog')]"
]
},
"execution_count": 3,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"bigrams = [b for b in zip(words[:-1], words[1:])]\n",
"bigrams"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"How do we use the bigrams to predict the next word given the first word?"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "fragment"
}
},
"source": [
" Return every second element where the first element matches the **condition**:"
]
},
{
"cell_type": "code",
"execution_count": 4,
"metadata": {
"slideshow": {
"slide_type": "fragment"
}
},
"outputs": [
{
"data": {
"text/plain": [
"['quick', 'lazy']"
]
},
"execution_count": 4,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"condition = 'the'\n",
"next_words = [bigram[1] for bigram in bigrams\n",
" if bigram[0].lower() == condition]\n",
"next_words"
]
},
{
"cell_type": "markdown",
"metadata": {
"collapsed": true,
"slideshow": {
"slide_type": "fragment"
}
},
"source": [
"(The quick) (quick brown) ... (the lazy) (lazy dog)\n",
"\n",
"Either “quick” or “lazy” could be the next word."
]
},
{
"cell_type": "markdown",
"metadata": {
"collapsed": true,
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"## Trigrams and Ngrams ##\n",
"\n",
"We can partition by threes too:\n",
"\n",
"(The quick brown) (quick brown fox) ... (the lazy dog)\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "fragment"
}
},
"source": [
"Or, the condition can be two words (`condition = 'the lazy'`):\n",
"\n",
"(The quick brown) (quick brown fox) ... (the lazy dog)"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "fragment"
}
},
"source": [
"\n",
"These are **trigrams**."
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "fragment"
}
},
"source": [
"We can partition any **N** number of words together as **ngrams**."
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"So earlier we got:"
]
},
{
"cell_type": "code",
"execution_count": 5,
"metadata": {
"slideshow": {
"slide_type": "fragment"
}
},
"outputs": [
{
"data": {
"text/plain": [
"['quick', 'lazy']"
]
},
"execution_count": 5,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"next_words"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "fragment"
}
},
"source": [
"How do we know which one to pick as the next word?\n",
"\n",
"Why not the word that occurred the most often after the condition in the corpus?"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "fragment"
}
},
"source": [
"We can use a **Conditional Frequency Distribution (CFD)** to figure that out!\n",
"\n",
"A **CFD** can tell us: given a **condition**, what is **likely** to follow?"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"## Conditional Frequency Distributions (CFDs) ##"
]
},
{
"cell_type": "code",
"execution_count": 6,
"metadata": {
"slideshow": {
"slide_type": "fragment"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"['The', 'quick', 'brown', 'fox', 'jumped', 'over', 'the', 'lazy', 'dog', 'and', 'the', 'quick', 'cat']\n"
]
}
],
"source": [
"words = ('The quick brown fox jumped over the '\n",
" 'lazy dog and the quick cat').split(' ')\n",
"print words"
]
},
{
"cell_type": "code",
"execution_count": 7,
"metadata": {
"collapsed": true,
"slideshow": {
"slide_type": "fragment"
}
},
"outputs": [],
"source": [
"from collections import defaultdict\n",
"\n",
"cfd = defaultdict(lambda: defaultdict(lambda: 0))"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"## Conditional Frequency Distributions (CFDs) ##"
]
},
{
"cell_type": "code",
"execution_count": 8,
"metadata": {
"slideshow": {
"slide_type": "fragment"
}
},
"outputs": [
{
"data": {
"text/plain": [
"{'and': {'the': 1},\n",
" 'brown': {'fox': 1},\n",
" 'dog': {'and': 1},\n",
" 'fox': {'jumped': 1},\n",
" 'jumped': {'over': 1},\n",
" 'lazy': {'dog': 1},\n",
" 'over': {'the': 1},\n",
" 'quick': {'brown': 1},\n",
" 'the': {'lazy': 1, 'quick': 2}}"
]
},
"execution_count": 8,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"for i in range(len(words) - 2): # loop to the next-to-last word\n",
" cfd[words[i].lower()][words[i+1].lower()] += 1\n",
"\n",
"# pretty print the defaultdict\n",
"{k: dict(v) for k, v in dict(cfd).items()}"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "fragment"
}
},
"source": [
"So, what's the most likely word to follow `'the'`?"
]
},
{
"cell_type": "code",
"execution_count": 9,
"metadata": {
"slideshow": {
"slide_type": "fragment"
}
},
"outputs": [
{
"data": {
"text/plain": [
"'quick'"
]
},
"execution_count": 9,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"max(cfd['the'])"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"## Whole sentences can be the conditions and values too ##\n",
"\n",
"Which is basically the way cleverbot works:\n",
"\n",
"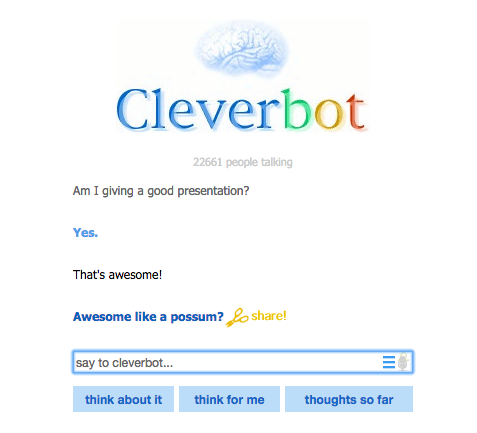\n",
"\n",
"[http://www.cleverbot.com/](http://www.cleverbot.com/)"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"## Random text! ##"
]
},
{
"cell_type": "code",
"execution_count": 31,
"metadata": {
"slideshow": {
"slide_type": "fragment"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"her reserve and concealment towards some feelings in moving slowly together . You will shew\n"
]
}
],
"source": [
"import nltk\n",
"import random\n",
"\n",
"TEXT = nltk.corpus.gutenberg.words('austen-emma.txt')\n",
"\n",
"# NLTK shortcuts :)\n",
"bigrams = nltk.bigrams(TEXT)\n",
"cfd = nltk.ConditionalFreqDist(bigrams)\n",
"\n",
"# pick a random word from the corpus to start with\n",
"word = random.choice(TEXT)\n",
"# generate 15 more words\n",
"for i in range(15):\n",
" print word,\n",
" if word in cfd:\n",
" word = random.choice(cfd[word].keys())\n",
" else:\n",
" break"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"## Random poems ##\n",
"\n",
"Generating random poems is simply limiting the choice of the next word by some constraint:\n",
"\n",
"* words that rhyme with the previous line\n",
"* words that match a certain syllable count\n",
"* words that alliterate with words on the same line\n",
"* etc."
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"\n",
"\n",
"[http://mule.hallada.net/nlp/buzzfeed-haiku-generator/](http://mule.hallada.net/nlp/buzzfeed-haiku-generator/)"
]
},
{
"cell_type": "markdown",
"metadata": {
"collapsed": true,
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"## Remember these? ##\n",
"\n",
""
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"## Mad Libs ##\n",
"\n",
"These worked so well because they forced the random words (chosen by you) to fit into the syntactical structure and parts-of-speech of an existing sentence.\n",
"\n",
"You end up with **syntactically** correct sentences that are **semantically** random.\n",
"\n",
"We can do the same thing!"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"## NLTK Syntax Trees! ##"
]
},
{
"cell_type": "code",
"execution_count": 11,
"metadata": {
"slideshow": {
"slide_type": "fragment"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"(S\n",
" (NP (DT the) (NN quick))\n",
" (VP\n",
" (VB brown)\n",
" (NP\n",
" (NP (JJ fox) (NN jumps))\n",
" (PP (IN over) (NP (DT the) (JJ lazy) (NN dog)))))\n",
" (. .))\n"
]
}
],
"source": [
"from stat_parser import Parser\n",
"parser = Parser()\n",
"print parser.parse('The quick brown fox jumps over the lazy dog.')"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"## Swaping matching syntax subtrees between two corpora ##"
]
},
{
"cell_type": "code",
"execution_count": 30,
"metadata": {
"slideshow": {
"slide_type": "fragment"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"(SBARQ\n",
" (SQ\n",
" (NP (PRP I))\n",
" (VP (VBP do) (RB not) (VB advise) (NP (DT the) (NN custard))))\n",
" (. .))\n",
"I do not advise the custard .\n",
"==============================\n",
"I do n't want the drone !\n",
"(SBARQ\n",
" (SQ\n",
" (NP (PRP I))\n",
" (VP (VBP do) (RB n't) (VB want) (NP (DT the) (NN drone))))\n",
" (. !))\n"
]
}
],
"source": [
"from syntax_aware_generate import generate\n",
"\n",
"# inserts matching syntax subtrees from trump.txt into\n",
"# trees from austen-emma.txt\n",
"generate('trump.txt', word_limit=10)"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"## spaCy ##\n",
"\n",
"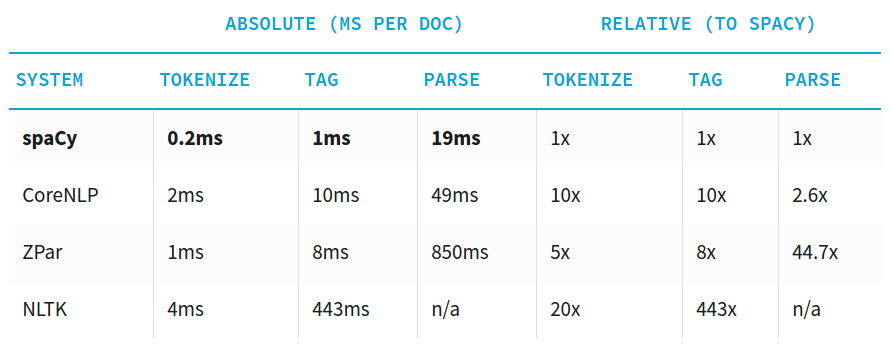\n",
"\n",
"[https://spacy.io/docs/api/#speed-comparison](https://spacy.io/docs/api/#speed-comparison)"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"## Character-based Recurrent Neural Networks ##\n",
"\n",
"\n",
"\n",
"[http://www.cs.utoronto.ca/~ilya/pubs/2011/LANG-RNN.pdf](http://www.cs.utoronto.ca/~ilya/pubs/2011/LANG-RNN.pdf)"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"## Implementation: char-rnn ##\n",
"\n",
"\n",
"\n",
"[https://github.com/karpathy/char-rnn](https://github.com/karpathy/char-rnn)"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"## Generating Shakespeare with char-rnn ##\n",
"\n",
"\n",
"\n",
"[http://karpathy.github.io/2015/05/21/rnn-effectiveness/](http://karpathy.github.io/2015/05/21/rnn-effectiveness/)"
]
},
{
"cell_type": "markdown",
"metadata": {
"collapsed": true,
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# The end #\n",
"\n",
"Questions?"
]
}
],
"metadata": {
"celltoolbar": "Slideshow",
"kernelspec": {
"display_name": "Python 2",
"language": "python",
"name": "python2"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 2
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython2",
"version": "2.7.12"
},
"livereveal": {
"scroll": true,
"theme": "simple",
"transition": "linear"
}
},
"nbformat": 4,
"nbformat_minor": 2
}